1.2 Tableaux unidimensionnels
Les tableaux en une dimension, que l’on peut considérer comme étant des “vecteurs”, c’est-à-dire de simples séquences de nombres, sont des éléments essentiels de tout calcul scientifique.
1.2.1 Construction à partir d’une fonction de NumPy
La bibliothèque Numpy offre plusieurs fonctions permettant de construire de tels tableaux unidimensionnels :
La fonction
np.linspaceDes tableaux de réels (floats) également espacés peuvent être créés à l’aide de la fonction
np.linspace(start,stop,num). Ainsi, le codepythonimport numpy as np x = np.linspace(-2,3,10,endpoint=True,retstep=False) print(x)construit un tableau de taille 10 (i.e. un tableau contenant éléments (nombres); étant la taille par défaut) :
le premier élément est
x[0]=-2.le dernier élément est
x[-1]=3(endpoint=True, valeur par défaut)le pas entre chaque valeur est alors donné par .
Si
retstep=True, la fonction retourne un tuple renfermant le tableau et le pas :pythonimport numpy as np x_vecteur,dx=np.linspace(-2,3,10,endpoint=False,retstep=True) print(x_vecteur,dx) print(type(x_vecteur)) print(type(x_vecteur[1])) print(type(dx))le pas entre chaque valeur est ici donné par .
La fonction
np.logspaceLa fonction
np.logspace(start,stop,num)produit quant à elle un tableau de nombres également espacés sur une échelle logarithmique. Les argumentsstartetstopse refèrent cette fois à une puissance de : le tableau commence à et se termine à .La fonction
np.arangeLa fonction
np.arange(start,stop,step)(“ArrayRANGE”) fournit une troisième manière de créer un tableau de nombres. Cette fonction est similaire à la fonctionrange(définie au semestre d’automne) permettant de créer des listes. Il est possible d’omettre le premier argument (qui prend alors la valeur ) et/ou le troisième argument (qui prend alors la valeur ).Cette fonction permet ainsi par exemple de construire un vecteur renfermant les valeurs réelles comprises entre
start=-2etstop=3(sans cette dernière valeur) séparées de la distancestep=0.2:pythonimport numpy as np x = np.arange(-2,3,0.2) print(x)Les fonctions
np.zeros,np.onesetnp.emptyParfois, il peut être utile de construire un vecteur dont toutes les composantes valent , ou ne sont pas initialisées (explicitement) :
pythonimport numpy as np v_zero = np.zeros(3) v_un = np.ones(5, dtype=int) v_vide = np.empty(2) print(v_zero, v_un, v_vide)Les fonctions
np.zeros(shape),np.ones(shape)etnp.empty(shape)ont chacune un argument obligatoire qui représente la forme du tableau (en fait, le plus souvent, il s’agit du nombre d’éléments dans le tableau), et un argument optionneldtypequi spécifie le type des données du tableau (bool,int,float(défaut) oucomplex).La fonction
np.arrayFinalement, un tableau peut être créé à l’aide de la fonction
np.array(object)avec pour arguments un container (liste, tuple ou tableau) et éventuellement un paramètredtype:pythonimport numpy as np print(np.array([-1,0,2.],dtype=complex))Si l’argument
dtypeest omis, la fonctionnp.arraypromeut automatiquement tous les éléments du tableau au type de l’entrée la plus générale du tableau (qui serait dans l’exemple ci-dessus le typefloat).Comme le montrent les quelques lignes de code suivantes, Numpy apporte à Python une grande diversité de types numériques :
pythonimport numpy as np x=0.123456789123456789123456789 # print('x =',x) print('Python (default) type :',type(x)) print('\n') # y=np.array([0.123456789123456789123456789]) print('y =',y) print('y[0] =',y[0]) print('y (Numpy default) type :',type(y)) print('y (Numpy default) data type :',y.dtype) print('y[0] (Numpy default) type :',type(y[0])) print('\n') # z16=np.array([0.123456789123456789123456789],dtype=np.float16) print('NumPy, 16bits type :',z16.dtype) print('z[0] =',z16[0]) print('\n') # z32=np.array([0.123456789123456789123456789],dtype=np.float32) print('NumPy, 32bits type :',z32.dtype) print('z[0] =',z32[0]) print('\n') # z64=np.array([0.123456789123456789123456789],dtype=np.float64) print('NumPy, 64bits type :',z64.dtype) print('z[0] =',z64[0])Dans la sortie produite, on note que le type
numpy.float64(ounumpy.double) fournit la même précision que le typefloatnatif.
1.2.2 Construction à partir d’un objet préexistant
Supposons que l’on définisse un vecteur x dont les composantes sont, par exemple, régulièrement espacées. Il peut être utile de définir un vecteur de la même taille et du même type que x. Trois constructeurs différents permettent d’obtenir un vecteur non initialisé (“vide”), un vecteur rempli de et un vecteur ne contenant que des : np.empty_like(), np.zeros_like() et np.ones_like().
Le code suivant fournit un exemple d’utilisation de ces trois constructeurs :
import numpy as np
x = np.linspace(0,9,10, dtype=int)
y_vide = np.empty_like(x)
y_zero = np.zeros_like(x)
y_un = np.ones_like(x)
print(y_vide, y_zero, y_un)
1.2.3 Opérations arithmétiques sur les tableaux
En Python, il est possible d’additionner, de soustraire, de multiplier ou de diviser deux vecteurs de même taille. Durant ces opérations, la ème composante du vecteur résultant est obtenue par l’addition, la soustraction, la multiplication ou la division des ème composantes des deux vecteurs :
import numpy as np
v_1 = np.array([-1,2,4])
v_2 = np.linspace(1,2,3)
print(v_1, v_2)
print(v_1+v_2, v_1-v_2)
print(v_1*v_2, v_1/v_2)
Les opérations d’addition et de soustraction de deux vecteurs sont identiques à celles définies en géométrie euclidienne. En revanche, avec des vecteurs habituels, le produit (scalaire) entre deux vecteurs, par exemple et , fournit un scalaire :
alors que dans NumPy le produit de deux ndarray est un tableau de même taille. “Vectoriellement”, cela aurait la signification suivante :
Remarquons également qu’en géométrie, la division d’un vecteur par un autre n’a pas de sens, alors que c’est une opération bien définie en Python :
En géométrie, on est fréquemment amené à multiplier un vecteur par un scalaire. Comme le montre le code suivant, NumPy autorise le même type de manipulations :
import numpy as np
v = np.array([-1,2,4])
print(5*v, v*5)
print(v/5, 5/v)
print(v**4)
print(v+5)
De plus, NumPy fournit des fonctions appelées universal functions (ou simplement ufuncs) qui peuvent être appliquées à un scalaire, de manière à produire un scalaire, ou à un tableau de façon à générer un tableau de même taille (en s’appliquant alors à chaque composante).
Parmi ces ufuncs, on trouve notamment les fonctions
- trigonométriques (
sin,cos,tan,arcsin,arccos,arctan) - hyperboliques (
sinh,cosh,tanh,arcsinh,arccosh,arctanh) - exponentielle (
exp) - logarithmes (
log,log10) - racine carrée (
sqrt) - permettant de manipuler des nombres complexes (
angle,real,complex,conj) - signe (
sign) - valeur absolue (
abs)
Ainsi, il est par exemple possible de construire très facilement un vecteur y dont les composantes sont les racines carrées des composantes correspondantes d’un vecteur x :
import numpy as np
x = np.linspace(0,9,10)
y = np.sqrt(x)
print(x)
print(y)
Notons que Python permet le calcul de la racine carrée d’un nombre négatif pour autant que l’on manipule des nombres complexes.
Rappel: La racine carrée de est le nombre complexe : . En Python, ce nombre se note j.
Dans le code suivant, la troisième ligne produit un “warning” (et retourne une composante nan (not a number)) parce que les éléments de v sont des nombres réels. La cinquième ligne en revanche s’exécute sans problème, les éléments de a*v étant complexes.
import numpy as np
v = np.array([-1,2,4])
print(np.sqrt(v))
a = complex(1,0)
print(np.sqrt(a*v))
Dans l’exemple suivant, NumPy calcule le logarithme où il le peut, et retourne nan si l’opération est illégale (calcul du logarithme d’un nombre négatif) et -inf pour le logarithme de zéro. Les autres valeurs dans le tableau sont retournées correctement :
import numpy as np
b = np.arange(-2.,4,1)
print(np.log(b))
Nous savons qu’une expression telle que , où est un vecteur n’a pas de sens. Dans le cas d’un tableau unidimensionnel de NumPy, une telle opération de comparaison est autorisée, élément par élément. On obtient un vecteur contenant les valeurs booléennes (valeurs “de vérité”) True ou False :
import numpy as np
v = np.linspace(-2,2,9)
y = v > 0
print(v)
print(y)
Un vecteur “logique” tel que le vecteur y ci-dessus permet par exemple de calculer facilement la valeur absolue de x :
import numpy as np
v = np.linspace(-2,2,9)
w = v
w[w<0]=-w[w<0]
print(w)
print(v)
Remarquons que pour conserver le vecteur v original, il faudrait remplacer la troisième ligne par w = v.copy().
1.2.4 Indexation et découpage (slicing) des tableaux
Les tableaux peuvent être découpés de la même manière que les listes et on accède à un élément d’un tableau unidimensionnel grâce à l’indice de l’élément placé entre des crochets qui suivent l’identificateur du tableau.
Pour comprendre comment fonctionne ce découpage, nous allons imaginer une expérience de chute libre, durant laquelle la distance verticale y (en mètres) parcourue par un objet est mesurée en fonction du temps t (en secondes). Les mesures permettent alors de remplir les deux tableaux suivants :
import numpy as np
y = np.array([0,1.31,4.99,10.9,19.7,29.8,43.9])
t = np.array([0,0.51,1.01,1.49,2.,2.5,2.99])
Il est possible de calculer la vitesse moyenne de l’objet en s’intéressant au taux de variation de la position par rapport au temps :
où les et les sont les éléments des tableaux y et t.
Pour ce faire, nous envisageons le découpage des tableaux y et t. Par exemple, pour y, nous allons considérer
print(y) # tableau complet des mesures de distance
print(y[1:]) # tableau amputé de la première mesure de distance
print(y[:-1]) # tableau amputé de la dernière mesure de distance
et faire la différence élément par élément (idem pour le tableau t) :
v_moyenne = (y[1:]-y[:-1])/(t[1:]-t[:-1])
print(v_moyenne)
La division se fait également élément par élément et le tableau v_moyenne obtenu contient un élément de moins que les tableaux y et t de départ. Il est alors naturel d’associer les vitesses obtenues à un nouveau tableau temporel dont les entrées correspondent à une moyenne entre deux mesures de temps successives:
t_moyenne = (t[1:]+t[:-1])/2
print(t_moyenne)
Les tableaux v_moyenne et t_moyenne renferment ainsi le même nombre d’éléments.
Nous verrons au chapitre suivant comment représenter de telles données expérimentales :
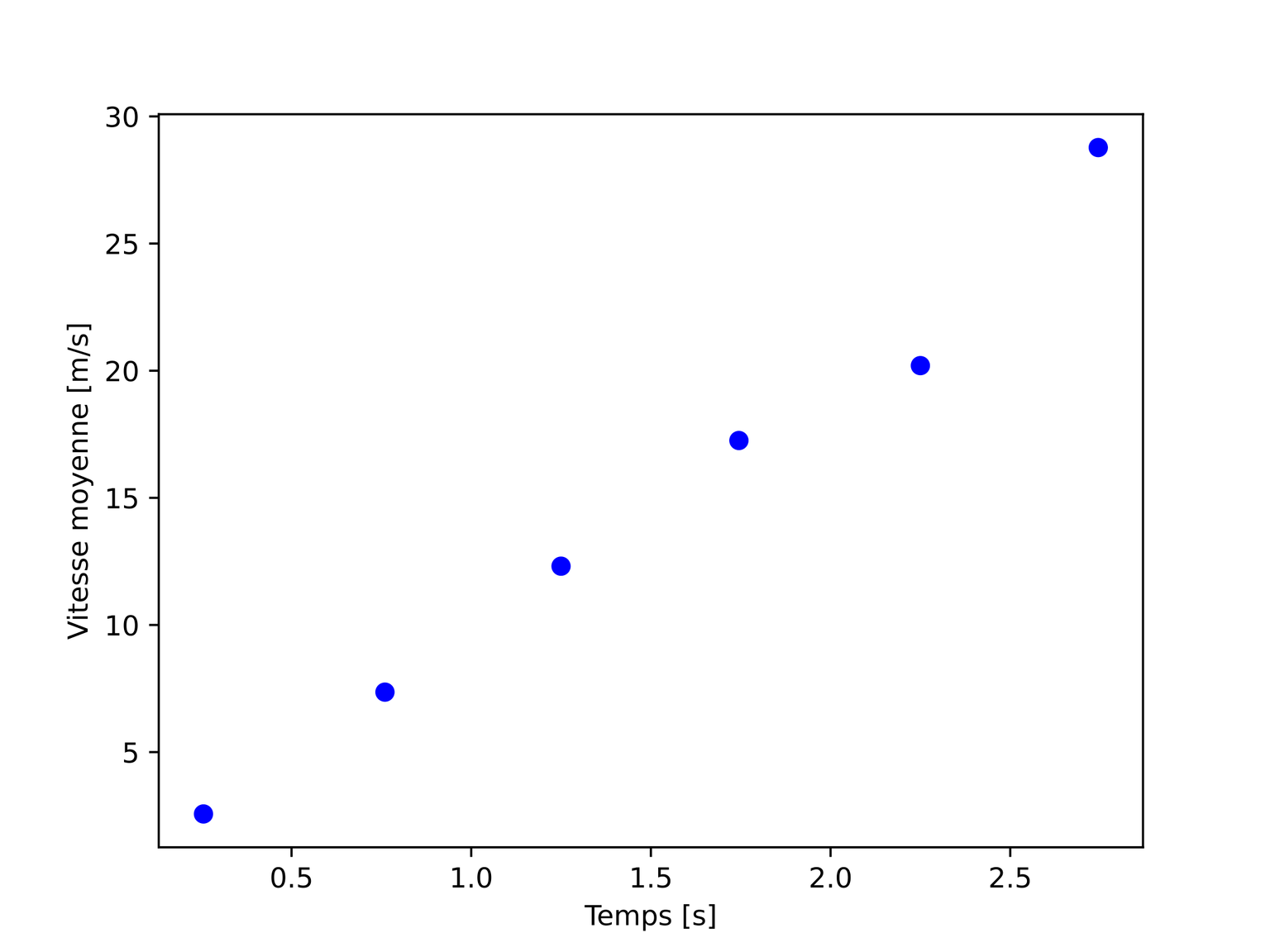
Une telle représentation permet d’avoir rapidement une “vérification” visuelle du comportement (linéaire) de la vitesse en fonction du temps dans le cas de la chute libre :
Polycopié rédigé par Roger Sauser, CMS. Sauf indication contraire, le contenu de ce document est soumis à une licence Creative Commons internationale, Attribution - Utilisation non commerciale - Partage dans les mêmes conditions 4.0 International (CC BY-NC-SA 4.0).
© 2026 Projet Botafogo. En savoir plus.