À propos du forum et de l'IA
Depuis le 2 décembre 2024, les questions posées sur la plateforme (sur
paragraphes du polycopié, exercices, quiz, etc) sont redirigées vers un
modèle de langage, qui produit des réponses automatiques.
Cette nouvelle fonctionnalité a vu le jour grâce au travail de Jérémy Barghorn, étudiant en master d'informatique, qui lui a consacré son projet de semestre à l'automne 2024.
Son initiative a ensuite été poursuivie et enrichie tout au long de l'année universitaire 2024-2025, aboutissant à une version plus robuste et performante mise en ligne le 8 septembre 2025, au début du semestre.
Depuis, un nouvel étudiant, Loïc Misenta, a rejoint l'équipe aux côtés de Jérémy afin de poursuivre le développement de l'outil et d'en perfectionner encore les performances.
Insistons tout de suite sur le fait que c'est un projet en cours: le
système est en constante évolution, son but étant de pouvoir fournir des
réponses raisonnables aux questions de mes étudiant.e.s, 24h/24h.
Donc on fait constamment des tests
beaucoup de tests sont encore en cours. Il est possible que certaines réponses
soient incomplètes ou nécessitent des ajustements. N'hésitez pas à me faire
part de vos retours, positifs ou négatifs.
Les modèles actuellement utilisés sont les suivants :
- GPT-OSS: un modèle
de 120 milliards de paramètres, open source, d'openAI. Ce modèle est utilise
pour classer les questions mettre en forme les réponses, faire la traduction,
etc.
- Deepseek : un modèle de 14 milliards de paramètres, open source, de
Deepseek. Ce modèle est plus petit mais est spécialisé dans les mathématiques.
C'est lui qui produit la partie mathématique des réponses reçues.
La particularité de ce projet est que ces modèles sont
hébergés à l'EPFL, sur des serveurs dédiés, et que les données (questions,
réponses, etc) ne sont pas envoyées à l'extérieur de l'EPFL. De plus notre
approche est open-source et vous pouvez retrouver les modèles que nous utilisons
sur la plateforme
HuggingFace.
Le but de ces modèles (plus petits que GPT-5 ou Gemini) est de fournir des
réponses adaptées à notre cours, et non pas de concurrencer les grands modèles
propriétaires. Notre but est principalement de vous aider dans votre
apprentissage des mathématiques, et non pas de fournir des réponses spoilant
tout l'exercice. C'est pourquoi vous verrez que souvent les réponses sont sous
le format ''éléments de réponse'' plutôt que des réponses complètes et
détaillées.
Si vous voulez avoir un peu plus de détails techniques, voici comment ça marche:
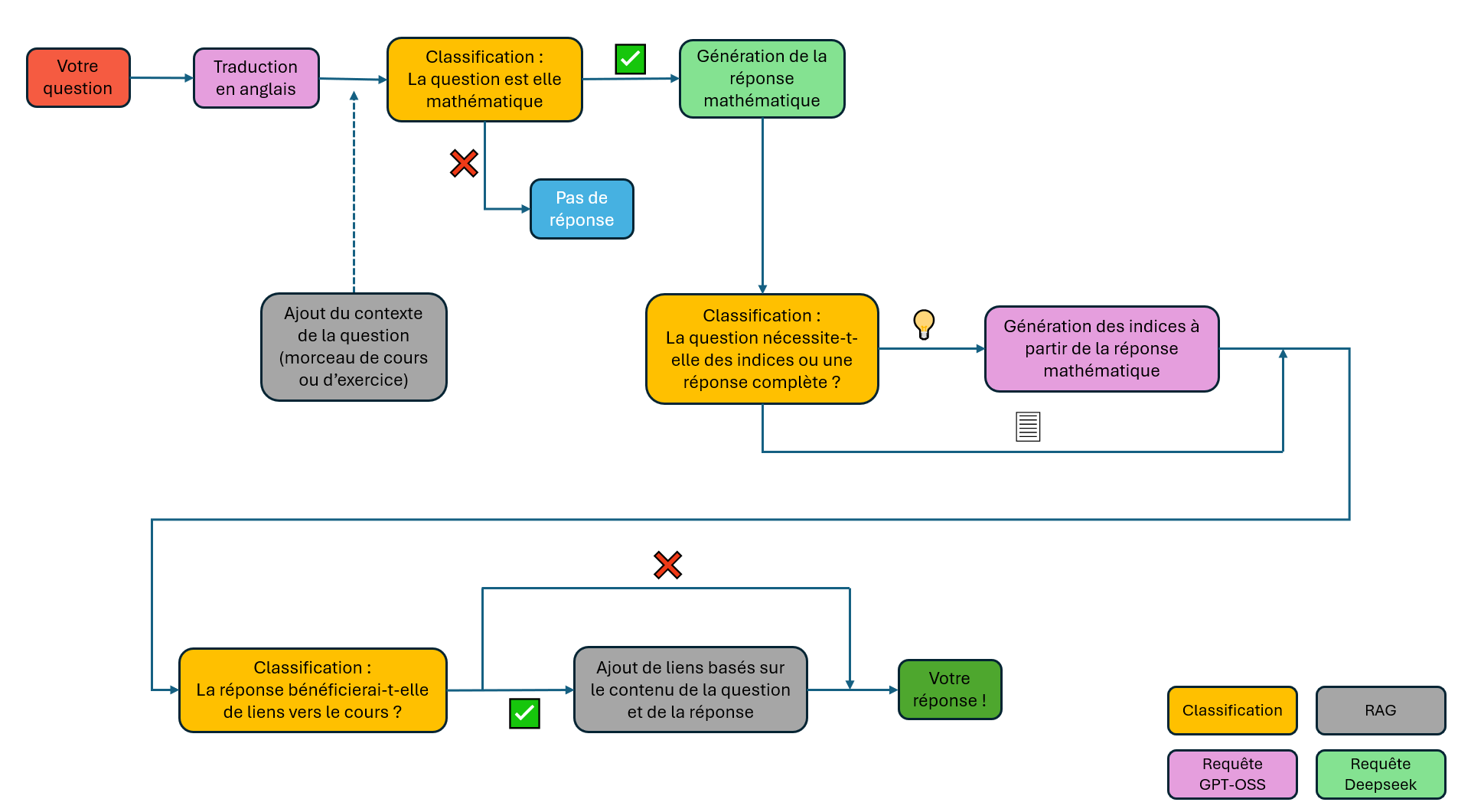
De base, Deepseek a des connaissances de maths assez poussées,
mais nous l'avons aussi
finetuné:
il a donc été entraîné sur
l'intégralité du cours, des exercices (avec leurs solutions),
et sur les quelques 2000+ questions postées (avec leurs réponses) sur
les forums depuis le début de leur existence (septembre 2023).
Comme dans toutes les utilisations de l'intelligence artificielle,
l'interprétation des réponses
produites par les modèles doit se faire avec quelques précautions:
- Malgré le fait qu'il a été entraîné sur tout mon matériel didactique, ses
connaissances antérieures lui font parfois utiliser un langage ou des résultats
que je n'utilise pas dans mon polycopié.
- Les modèles ont été
entraîné spécifiquement pour répondre à des questions de maths, donc
inutile de lui demander quelles sont les meilleures options bière-pizza de Lausanne!
- Comme souvent lorsqu'on interagit avec un modèle de langage,
les réponses font parfois un peu sourire. Soit parce qu'elles contiennent des
choses extraordinairement fausses, soit parce qu'elles sont à côté du sujet.
De manière générale,
- je validerai les réponses que j'estime acceptables au vu
de mon cours et de ma façon d'enseigner. Ma validation est visible au bas de la
réponse, par un petit ''vu'' vert, à gauche:
- je supprimerai les réponses que j'estime trop mauvaises ou
inadaptées
- j'éditerai les réponses que j'estime assez bonnes pour être
gardées, malgré une ou deux imprécisions qu'il faut modifier. Mes modifications
seront signalées par ''Edited by SF'' à la fin de la réponse.
Pour ce qui est des utilisateurs/trices:
- Posez vos questions en \(\LaTeX\) plutôt qu'avec des captures d'écran! Les modèles
peuvent vous aider seulement si vous lui soumettez du texte.
- De manière générale, apprenez à lire les réponses des modèles dans le but de
trouver des éléments de réponse plutôt que des réponses très précises!
- Il est très important de liker une réponse que vous jugez utile: ceci nous
aidera pour les entraînements futurs du modèle
Bien sûr, vous pouvez aussi liker une réponse que vous lisez,
même si ce n'est pas vous qui avez posé la question.
- Si vous ne comprenez pas la réponse de Qwen, et si je l'ai laissée sur le
serveur, vous pouvez toujours continuer le thread en demandant des explications,
et c'est moi qui y répondrai.
(Remarquez que le modèle n'est pas un chatbot, inutile de lui demander
des précisions sur quelque chose qu'il a déjà dit: il répond à la
question de départ une fois puis oublie tout.)
- Comme le modèle répondra à vos questions 24h/24h, je ne pourrai pas toujours
vérifier ses réponses avant que vous les lisiez.
Cela signifie que si vous lisez une réponse qui vient d'arriver, avec aucune
trace de mon passage, ce que vous en faites est
sous votre entière responsabilité!
Il est donc utile de revenir de temps en temps pour voir si je ne suis pas
intervenu plus tard sur une réponse que vous avez déjà lue.

